

Today, we’d like to introduce you, dear tech enthusiasts, experts, and those who are simply interested, to our new series “Interview with our Experts.” Our CEO, Eric from filedgr, is a big fan of data use cases, data management, and ultimately, databases and data structures. In this interview, he introduces you to the Log-Structured Merge Trees (LSM Tree).
As he puts it, “In my opinion, one of the most important data structures driving our modern data tools and… blockchains.”
The Emergence of LSM Trees 🪴
Kim: Hello Eric, it’s great that you took the time to speak today. Can you tell us what LSM Trees are and why they are so important in modern data processing?
Eric: Certainly. LSM Trees are not only elegant and efficient data structures, but they also represent a paradigm shift in our approach to database management and optimization in large-scale, high-throughput environments. LSM Trees are essentially key-value stores that can quickly insert data and respond to queries like “Give me the data for this key: myKey” in no time.
LSM Trees were designed to efficiently manage large volumes of data. They enable fast data insertions, deletions, and searches. The foundations for this were laid by Michael L. O’Neil and other researchers in the 1990s. O’Neil is a respected computer scientist specializing in database technology. His work, including the groundbreaking paper on LSM Trees, has helped make LSM Trees a central element in many modern database systems. https://www.cs.umb.edu/~poneil/lsmtree.pdf
- LevelDB (Google)
- RocksDB (Facebook)
- MyRocksDB (MySQL fork with a RocksDB layer)
- BadgerDB
When LSM Trees are distributed across multiple servers, coupled with consistent hashing, we can add the who’s who of big data-related databases, such as:
- Cassandra (Apache)
- ScyllaDB
- DynamoDB (AWS)
Kim: Very interesting. And how exactly do LSM Trees work?
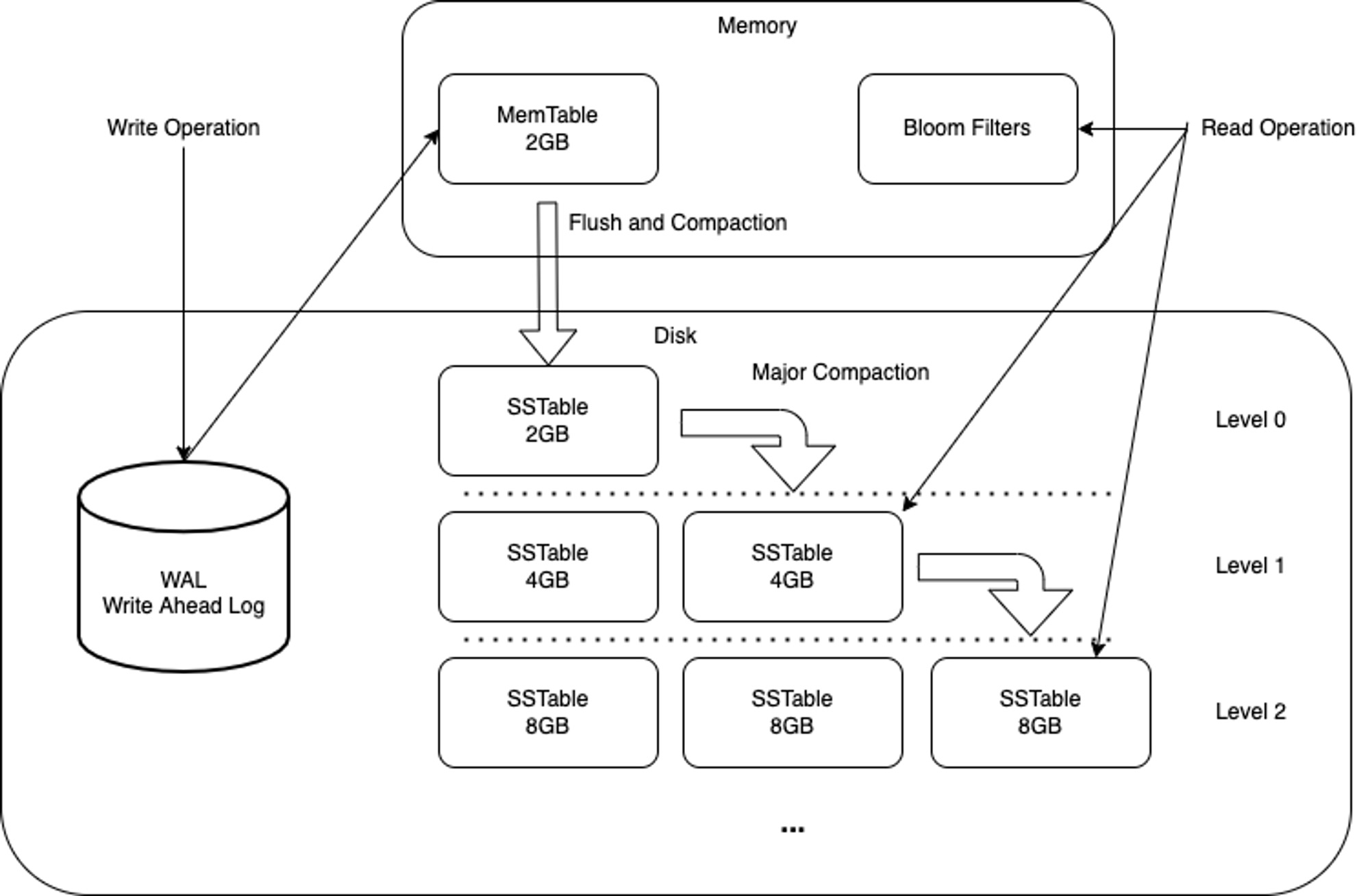
Eric: The LSM Tree is a multi-tiered data structure that uses Write-Ahead Logging and merging to achieve superior performance for write-intensive applications. It mainly consists of two components: an in-memory table (MemTable) and a set of persistent tables (SSTables).
Data Insertion: New entries are first written to the MemTable. Once the MemTable reaches a certain size threshold, it is flushed to disk as a SSTable. This process ensures fast data insertions without the immediate burden of disk I/O.
Merging and Compaction: To maintain efficiency in queries, LSM Trees periodically merge multiple SSTables into larger, contiguous ones. This compaction process is crucial for optimizing read operations and minimizing disk storage requirements.
Elegance is when the inside is as beautiful as the outside.”
– Coco Chanel
Kim: What makes LSM Trees so special compared to other data structures?
Eric: As we can see from the schemas provided above, the multiple SSTables appear to be made for parallel processing. However, this does not always lead to significant performance gains with disk I/O, so LSM Trees implement a very elegant optimization. Each SSTable stores a Bloom Filter. This is a probabilistic data structure to quickly check if it’s even worth looking for a key in the SSTable. Before scanning the table, the Bloom Filter asks if a key is likely to be found, it answers: Maybe this key is in here, you should check! Or: I’m 100% sure, this key is not in my SSTable, check the next one.
Kim: Talk to us about the role of LSM Trees in blockchains. How do they fit together?
Eric: Blockchains greatly benefit from the strengths of LSM Trees – fast write access, scalability, and fault tolerance. Blockchains must continuously process and store transactions, requiring high write performance. LSM Trees enable this efficiency by providing fast data insertions while ensuring data integrity through Write-Ahead Logs, even in case of failure. In short: Blockchains need to write data fast: Check; need to scale: Check; and ultimately, they need to be fault-tolerant: Check 😉
Kim: Finally, what should developers and companies consider when deploying LSM-based databases?
Eric: There are three main things to consider.
- Write Optimization: LSM Trees are designed with write optimization in mind, making them an ideal choice for protocol-intensive applications and write-intensive workloads.
- Scalability: Thanks to their merging and compaction strategies, LSM Trees can handle massive datasets while maintaining operational efficiency.
- Fault Tolerance: Using Write-Ahead Logs ensures data integrity even in the event of system crashes or power outages.
Kim: Thank you for providing these wonderful insights into LSM Trees. Your expertise will certainly help many who want to dive deeper into the subject.
Eric: Until next time, stay curious, and let the data guide your journey.
🦉


